
System Architecture
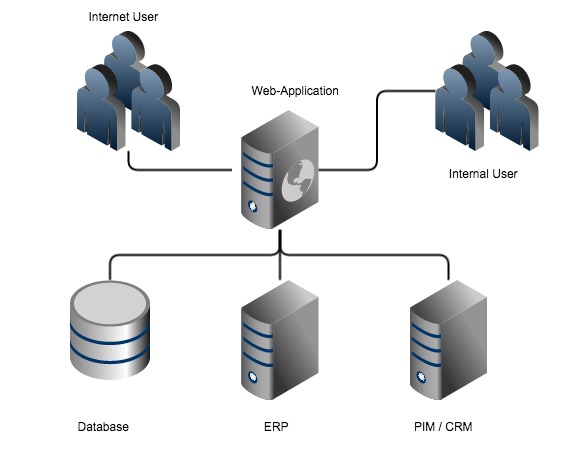
Whether you have a regular homepage, a shop system or a blog platform, your web application is where your customers or your target audience make contact. And because you want to channel all of your content and data through this system, you connect all internal systems to this web application.
Import-Export techniques increase the time-to-market, because the data is not updated until the next import. They are also old-fashioned, and stress the server because they require a lot of system resources during processing. So long running, resource-heavy jobs usually run once a day or over night. Another disadvantage is that they do not scale up - doubling the amount of data requires double the time to process.
To speed things up, you cound try to avoid Import-Export techniques as much as possible and instead use Direct-Data-Access techniques. In short, this means that data isn’t physically moved to your web application, but stays in the backend system it comes from, creating an interface that provides the data as it is requested. This reduces the time-to-market, as data changes are visible immediately.
The problem is, going this route, is only swapping one inefficient approach for another. The interfaces link the web application to your internal systems in real-time, which makes data format, security and availability a huge concern. Performance becomes an issue as well, first of all the performance of the web application can only be as fast as the slowest interface is and each interface used to get data slows down the page even more.
Often a mixed approach is used, trying to find the happy-medium between Import-Export and Direct-Access that meets the expectations of the customer. This is a standard practice and has worked well for a lot of projects. But can´t we do better?
The Core Problem
The Core Problem
In my opinion, when designing web applications the system architecture often has one major flaw. The web application is responsible for handling the internet traffic, managing data and accessing the internal systems. Common content management or shop systems like Wordpress or Magento are a good example of this, as they are centralized systems and the lynchpin is the web application itself. They manage your data, implement your business processes and provide an user interface for all administrative tasks.
But having a flexible and scaleable system architecture that is centralized is a contradiction!
A web application has to meet the requirements of different branches and can only fail to meet them all - you can´t stay dry and wet at the same time! For page rendering, speed is everything - the less logic, the better. But that means to avoid interface calls which would lead to Import-Export for getting the data, which …
Clearly, we are trapped here. We usually find a compromise that works for some time. Why can´t a shop or content management system scale the same way your business does?
A Possible Solution?
A Possible Solution?
Instead of having the systems lynchpin on the web application or some other IT-System, what if we promote the data itself and make the data the center of the system architecture? Let’s explore this idea on a shopping website.
Obviously, some kind of data processing unit that is both able to handle incoming data and write it to a database for persistent storage is necessary. This unit, therefore, is the core unit of our system architecture. As sequential data processing is slow and does not scale-up well, parallel data processing is required. With, for example, Apache´s ActiveMQ, RabbitMQ or Redis, multiple worker processes can be run on the core unit. Each of them just writing a single record to the database. So instead of writing 100 records, one after the other, 50 records can be written parallel by running 50 worker processes.
Worker processes and a database for persistent storage is a good start for our shopping website. Next up is a system for searching, filtering and sorting the data - something like Apache´s Solr or ElasticSearch. A search engine is specialized in giving answers very fast, while a database has other advantages like persistence for example. To keep the search engine up to date, incoming data is not only written to the database, but it is also updated in the search engine.
Next in line are the business systems that provide the data for our shop. To start simple, we just add an enterprise resource planning system (ERP) for prices and stock information. Using Import-Export seems like a good option. It provides stability and protects the ERP system from direct access. Important here is, that the data is processed in parallel by the workers to store the data and update the search engine. This scales linear! If, for example, the number of articles in our shop doubles but the processing time should not, we just have to double the number or worker processes by adding more hardware resources.
So we have the database, the search engine, and our core unit, but we still just have data without form, layout, or design. A central part of every web application is merging the data and the design. Whether you call it templating or page rendering, the result is the same - the data is fetched, processed through some kind of template system or engine to generate a HTML document sent to the user’s browser.
If we think back to the idea of having the data in the center of our architecture, pages and data from the template should not be assembled on demand, they would have to be assembled to a web page when the data is provided or changed. Respectively, all pages would have to be re-assembled when a template is modified. Luckily, we already have a few worker process waiting to move the data to the database and search engine, so it follows to have them re-render the page as well. The same thing happens when the data is modified - if you fetch new prices or stock data from the ERP, the worker processes re-render the pages that have to be modified. Again, this is parallel processing - it is not important how long it takes to render one HTML page. If thousands of pages have to be rendered quickly, just enough worker processes are required. Each worker renders one page until all pages are done.
Other systems can be added the same way. If you have a PIM providing product information like images and text, just update the database and search engine on modification and re-render pages if necessary. If you need an application for maintaining or reporting your customer data, just add it.
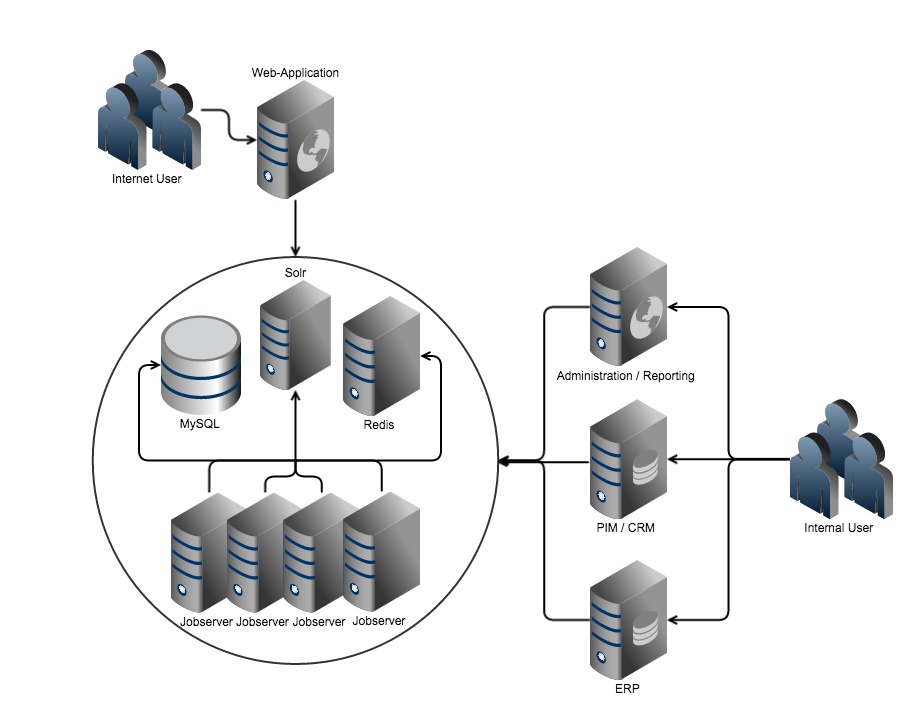
What does that leave your shop system at? Basically just the shopping cart and the checkout is left, thus simplifying your shop system to the minimum required. Category and product pages are pre-rendered, logic is reduced to the essentials and the rest is static content and incredibly fast in comparison to a shop system which loads product data from a database and processes a template to fill in the data.
Often caching is sold here as a "solution". But caching for performance is the wrong idea. Caching should be used to increase the amount of load a system can handle. So instead of using system resources to process a page on every request, the cached result is returned on consecutive requests leaving the system resources free to do other things.
With only a few components, each specialized for a single task, changes and modifications for a single systems can be implemented individually. The data becomes the center of your system architecture. The data is stored in the database, fetched from a search engine and a message system organizes the parallel processing.
Final Words
Final Words
Modern web applications like spryker or large websites like BBC ( BBC-Blog), for example, are constructed with a similar architecture as the one I have described. So focusing on your data instead of on an application is, in my opinion, a worthwhile change of perspective.