
PHP Workers
PHP is a great programming language for web applications. It´s wide support for database systems and internet protocols make it the right choice for a lot of web applications. But for high performance websites it is key to prepare as much as possible. The less logic on the request, the faster the website. The faster the website, the more users can the server process. But PHP is a language for webservers, running as apache module or fcgi process on a per-request-basis. Not exclusively.
Command Line Interpreter
Command Line Interpreter (CLI)
PHP is shipped with a command line interpreter. This allows the code to be run without a webserver. Still the code runs only when it is executed manually or it can run periodically via cron. Usualy this technique is used for time consuming tasks. For example generating an export file, sending lots of emails or processing and importing a data file. But there are two problems, scaleability and runtime. If the data that is processed increases, the runtime increasing accordingly. Somtimes it even increases exponentialy, increasing the problem even more.
The usual solution is to split the long running task into smaller chunks that are executed more often. For example instead of sending 1000 newsletter emails at once, packages of 100 emails are sent every hour. In addition the code is optimized to reduce the runtime, but both approaches only delay the inevitable. At some point the system is no longer able to handle the amount of data your bussines requires.
Lets do some numbers to elaborate on the problem:
An import of 100.000 data sets that takes 0,5 Sek per record, takes roughly 14
hours to complete. 200.000 data sets will take 28 hours. By Optimizing the
script some time can be saved, but a reduction of 10% to 20% (0,4 Sek instead of
0,5 sec) is a huge improvement that saves only 1 or 2 hours in total. And what
if all potential for optimization has been exploited and it still takes too
long?
Let´s try another approach. Instead of having one script importing the 100.000 data sets what if there are two, each importing 50.000 data sets? Having two PHP processes each working half of the data parallel saves 50%! 4 save 75%!! 10 save 90%!!! You see where this is going?
Dont get me wrong, im not saying “do not optimize”, but there are limits to optimization. Of course there are limitations for parallelization as well, but they are different as system resources limit the amount of parallel PHP processes that can run simultaniously. Or, for example a lot of workers writing to a database create a bottleneck and overload the database. These limits can be circumvented externaly, they are independent from logic or the amount of data and there are good strategies for scaling hardware or resolve bottlenecks with cluster solutions or loadbalancing.
In order to process data parallel the code has to be organized differently. Dependancies have to be resolved in such a way, that each operation is atomic. That means the operation does not depend on other operations as there is no controll or guarantee if or when the other opreration is executed.
The Parallel Processing
The Parallel Processing
The Queue
Queuing is a simple pattern used, for organizing parallel operations. A simple queue example is a database table, the initial trigger, some user input or cron job, stores one entry in that table for each data set to be processed, instead of processing it. A worker process periodically check this table, takes the data set and processes it. But using a database table as a queue, is not very efficient. There are other tools better suited or even specialized for this task. Redis, RabbitMQ or Apache ActiveMQ for example. And on standard computer hardware you can run many worker processes depending on how much RAM is required by your tasks. But 128MB for example, for each PHP process, is a good starting point and depending on the RAM of your server you can determin your self how much worker processes are supported.
The Worker processes and solo
The worker process is a simple PHP script running on the command line (CLI). It implements an infinite loop and periodically checks the queue for something to do. Because PHP has the unlovely attitude of allocating memory and not properly releaseing it again, the workers need to be killed and restarted from time to time. For example after a random number between 1000 and 2000 commands that it has processed. In order to have the PHP worker process restarted again we use solo, a tiny but clever Perl script. With this, each worker process blocks a port number if running and is startet if the port is somehow not blocked. The solo script is run periodically via cron and checks the port every minute for example.
The Commands
The commands basically are the single tasks that you store in the queue. Each
command is processed by a worker process and does one single thing. Remember,
commands are processed parallel so waiting for another command to finish should
be avoided. Also the data required for processing has to be stored in the
command or it has to be fetched by the command as it needs to operate alone and
independent (atomic).
There are a few rules for “commands” to keep
in mind:
- Hands to your self
Dont access global objects, they may not be accessible. - Ask, dont take
If you need someting ask your parents (worker process or queue) or create objects yourself. - Dont leave your toys around
Dont create global objects, and clean up the objects that you created. - Dont talk to strangers
Do never ever access other commands.
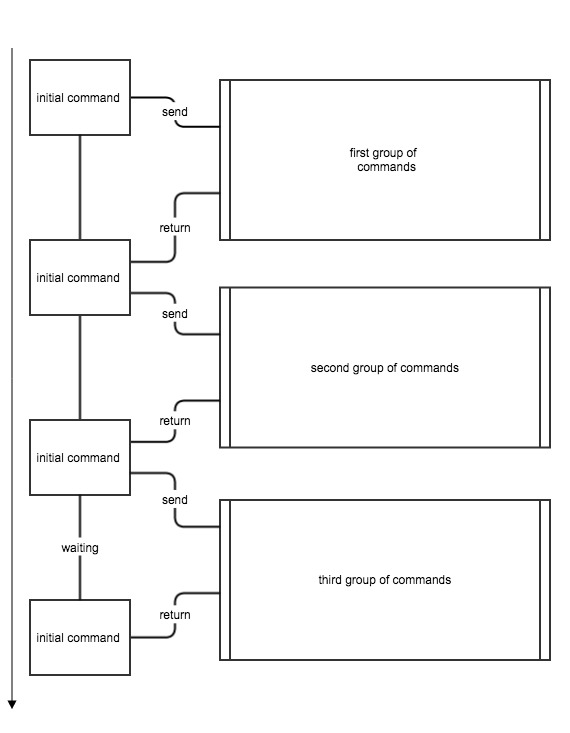
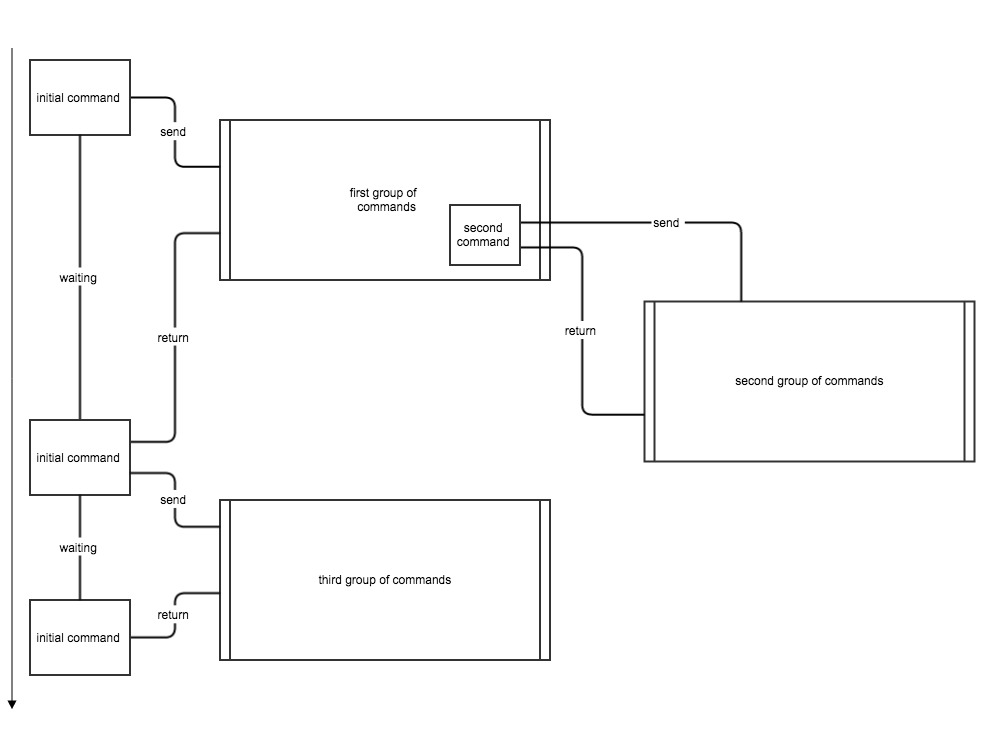
The parallel processing is started with an initial trigger, sending commands to the queue. What if the trigger is reduced to just sending one “initial” command to the queue instead. This command then splits the data and sends other commands. The worker processes waiting will start processing the new commands while the initial command is still sending. Grouping the commands enables the transfer of large and complex processes to your worker processes. This means that one worker process is blocked by a long running operation, but this operation sends lots of commands that all belong to the same group and waits until all commands of this group have been processed, it then continues to send the next group of commands.
It is also possible to have commands inside a group sending commands, if they belong to the same group, the initial command will wait for them to finish as well. If they do not belong to the group they are processed parallel.
Conclusion
Conclusion
Typical Scenario
There are certain situations where the use of worker processes for parallel processing is obviously helpfull. For example a bulk import, or fetching and processing of images for a shop system. But if you are able to change the typical architecture of a web application to a more process oriented approach you may end up with a worker process re-assembling a web page when the template or the content is modified instead of when it is requested by a user. See my article on System Architecture for more thoughts on this topic.
Known Pitfalls
During my work with parallel processing i have stumbled across some problems that i want you to keep in mind.
- PHP resource handles: As the commands have to be atomic, you can never rely on resource handles like database connections, file handles etc. Each command has to create the resources it requires on its on and clean them up afterwards.
- MySQL auto increment: Writing to a table from multiple worker processes simultaniously is not handled well by MySQL regarding auto increment columns and “on duplicate key update” statements. A good solution is to have the initial command store the current ID in Redis and increment it there instead using MySQL´s auto increment. A detailed analysis of the problem can be found on this blog entry.
Final Thoughts
With PHP worker processes it is possible to shift the architecture of web applications. No longer dynamic access, request-orientend, on-demand services, but static, prepared, pre-rendered content. Only user interaction is dynamic. The rest is done with parallel processing. If you would like to explore the potential of parallel processing with PHP, I recommend my Rq-Library available as Zend Framework 2 Module as a starting point. Have your own worker processes waiting to do the heavy lifting instead of scaling the hardware of the webservers.